
Below is a brief summary of our method, and the key results presented in the paper. To read an arxiv preprint of the original paper, click on the title above. For a more detailed summary, including more results not presented in the paper please click here.
Introduction
The human capacity for recognizing complex visual patterns is believed to arise via a cascade of transformations, implemented by neurons in successive stages in the ventral visual stream. Several recent studies have suggested that representations of deep convolutional neural networks trained for object recognition can predict activity in areas of the primate ventral visual stream better than models constructed explicitly for that purpose (Yamins et al. 2014, KhalighRazavi et al. 2015). On the other hand, several other studies have used synthesis techniques to generate images that indicate a profound disconnect between the sensitivity of these networks and that of the human visual system. Szegedy et al. revealed a set of image distortions, imperceptible to humans, that cause their networks to grossly misclassify objects within images. Similarly, randomly initialized images yielding reliable recognition from the network are uninterpretable 'fooling images' to human viewers (Nguyen et al. 2015) . These results have prompted efforts to understand why failures of this type are so consistent across different model architectures, and to develop more robust training methods (Goodfellow et al. 2014).
From the perspective of modeling human perception, these synthesis failures suggest that representational spaces within deep neural networks deviate significantly from that of humans, and that methods for comparing representational similarity, based on fixed object classes and discrete sampling of the representational space, are insufficient to expose these failures. Despite this, many recent publications have begun to use deep networks trained on object recognition as models of human perception, explicitly employing their representations as perceptual metrics or loss functions. If we are going to use such networks as models for human perception, we must reckon with this disparity.
Recent work from Dodge and Karam analyzed deep networks' robustness to visual distortions on classification tasks, as well as the similarity of classification errors that humans and deep networks make in the presence of the same kind of distortion. Here, we aim to accomplish something in the same spirit, but rather than testing on a limited set of hand-selected examples, we develop a model-constrained synthesis method for generating test stimuli that can be used to compare the layer-wise representational sensitivity of a model to human perceptual sensitivity. Utilizing Fisher information, we isolate the model-predicted most and least noticeable changes to an image. We test the quality of these predictions by determining how well human observers can discriminate these same changes. We test the power of this method on six layers of VGG16, a deep convolutional neural network (CNN) trained to classify objects (Simonyan and Zisserman 2015). We compare these results to those derived from models explicitly trained to predict human sensitivity to image distortions, including both a 4-stage generic CNN and highly-structured models explicitly constructed to mimic the early visual system. We thus compare how different architectures constrain predictions of human sensitivity.
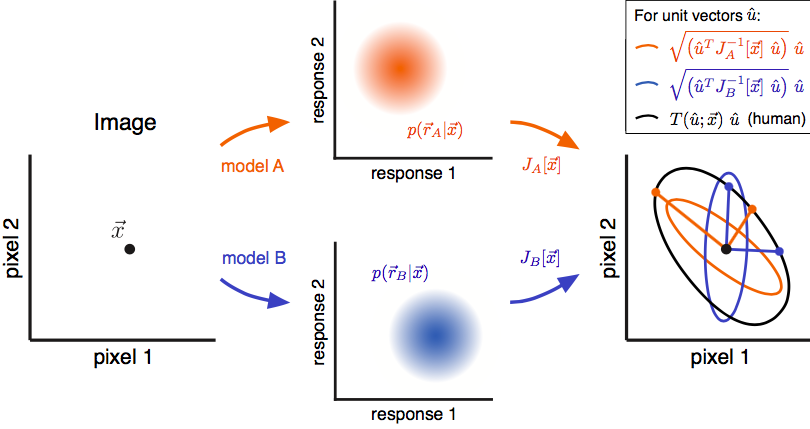
Measuring and comparing model-derived predictions of image discriminability.
Two models are applied to an image (depicted as a point x in the space of pixel values), producing response vectors r_A and r_B. Responses are assumed to be stochastic, and drawn from known distributions p(r_A|x) and p(r_B|x). The Fisher Information Matrices (FIM) of the models, J_A[x] and J_B[x], provide a quadratic approximation of the discriminability of distortions relative to an image (rightmost plot, colored ellipses). The extremal eigenvalues and eigenvectors of the FIMs (colored lines) provide predictions of the most and least visible distortions. We test these predictions by measuring human discriminability in these directions (colored points). In this example, the ratio of discriminability along the extremal eigenvectors is larger for model A than for model B, indicating that model A provides a better description of human perception.